*""" This tutorial is based on python 2.7"""
Python 2 Source Code //: # (选Gzipped source tarball)
Python 3 Source Code //: # (选Gzipped source tarball)
PYPY Source Code //: # (选Download repository)
lambda
lambda can be used to create small anonymous functions.
lambda是def func()的语法糖,但它的定义只能是单个的expression.
lambda的使用方法是: 定义输入参数,定义返回值,好了,这是你要的函数。
lambda的一个常用用法是用于各类筛选函数(key=func)
# 球员属性值
>>> Ronaldo = {'skill': 9, 'speed': 10, 'teamwork': 8, 'name': "Cristinano Ronaldo"}
>>> Messi = {'skill': 10, 'speed': 8, 'teamwork': 9, 'name': "Lionel Messi"}
>>> Neymar = {'skill': 9, 'speed': 9, 'teamwork': 9, 'name': "Junior Neymar"}
>>> player_list = [Ronaldo, Messi, Neymar]
# 寻找谁是团队毒瘤
>>> min(player_list, key=lambda x: x['teamwork'])
{'name': 'Cristinano Ronaldo', 'skill': 9, 'speed': 10, 'teamwork': 8}
# 谁技术最好
>>> max(player_list, key=lambda x: x['skill'])
{'name': 'Lionel Messi', 'skill': 10, 'speed': 8, 'teamwork': 9}
# 将球员按绝对速度从大到小排序
>>> sorted(player_list, key=lambda x: x['speed'], reverse=True)
[{'name': 'Cristinano Ronaldo', 'skill': 9, 'speed': 10, 'teamwork': 8},
{'name': 'Junior Neymar', 'skill': 9, 'speed': 9, 'teamwork': 9},
{'name': 'Lionel Messi', 'skill': 10, 'speed': 8, 'teamwork': 9}]
另一个用法是用在简单的函数生成器里:
def make_multiplier(factor):
return lambda x: x * factor
>>> multiple_3 = make_multiplier(3)
>>> multiple_3(5)
15
当然single expression从理论上而言允许你写出无限长的语句,但是你最好不要这样用它。lambda应当用于简短的函数定义里。以下是一个toy case, I wrote it for fun, please don't use it in practice.
complicate_lambda_func = lambda *args, **kwargs: \
"No message" if len(args) + len(kwargs) < 2 \
else "Yes, sir!" if ('id' in kwargs and kwargs['id'] == 'General') \
else "There is no door for you" if 'alibaba' in args \
else "It's already long enough, let's top here"
Descriptors
Definition and Introduction
In general, a descriptor is an object attribute with "binding behaviour", one whose attribute access has been overriden by methods in the descriptor protocol.__get__(), __set__() or __delete__() forms the descriptor protocol.
If any of these three methods are defined for an object, the object is said to be a descriptor.
The default behavior for attribute access is to get, set, or delete the attribute from object's dictionary.
For instance, a.x has a lookup chain starting with a.__dict__['x'], then type(a).__dict__['x'], and continuing through the base classes of type(a) excluding metaclasses. Metaclass Introduction
If the looked-up value is an object in whinch defined one of the descriptor methods, then Python may override the default behavior and invoke the descriptor instead(if it is a data-descriptor and __getattribute__ not overriden).
Descriptors only work for new style objects and classes. (classes which inherits from object or type)
Descriptors are generally used. They are mechanism behind properties, methods, static methods, class methods, and super().
They are used throughout Python itself to implement the new style classes. Descriptors simplify the underlying C-code and offer a flexible set of new tools for everyday Python programs.
Descriptor Protocol
descriptor.__get__(self, obj, type=None) --> valuedescriptor.__set__(self, obj, value) --> Nonedescriptor.__delete__(self, obj) --> None
non-data descriptors are those with only __get__ method, meanwhile data descriptors does have __get__ plus any or both of __set__ method and __delete__ method.
data descriptors precede instance's dictionary, meanwhile non-data descriptors has lower priority than instance's dictionary.
If you want to make a read-only data descriptor, you can defining its__set__() method like this:
def __set__(self, obj, value):
raise AttributeError("This is a read-only data-descriptor!")
Invoking Descriptors
You can call descriptor.__get__(obj) directly. Or you can trigger it upon attribute access(object.my_attr).
For objects, the machinery is in object.__getattribute__() which transforms b.x into type(b).__dict__['x'].__get__(b, type(b)).
For classes, the machinery is in type.__getattribute__() which transforms B.x into B.__dict__['x'].__get__(None, B). In pure Python, it looks like:
def __getattribute__(self, key):
"Emulate type_getattro() in Objects/typeobject.c"
v = object.__getattribute__(self, key)
if hasattr(v, '__get__'):
return v.__get__(None, self)
return v
The important points to remember are:
* descriptors are invoked by the __getattribute__() method
* overriding __getattribute__() prevents automatic descriptor calls
* __getattribute__() is only available with new style claesses and objects
* object.__getattribute__() and type.__getattribute__() make different calls to __get__().
* data descriptors always override instance dictionaries.
* non-data descriptors may be overridden by instance dictionaries. (Note here we write instance, not Class!)
* In Class, the non-data descriptor is triggered via `Class.__dict__`,
but you can't change `Class.__dict__` once that class is loaded. So overriden issue mentioned above is not possible in Class.
The object returned by super() also has a custom __getattribute__() method for invoking descriptors. The action super(B, obj).m searches obj.__class__.__mro__ for the base class A immediately following B and then returns A.__dict__['m'].__get__(obj, B)
Descriptor激活机理描述:
假设我们有一个类MyClass,my_instance是由类MyClass生成的实例。
当我们调用MyClass.attr时,我们会去MyClass的__dict__里寻找"attr"key,如果没有该key,返回AttributeError;
如果有"attr"key, 且该key对应的value有__get__方法,Python会调用该方法,向该方法传入两个值:None, MyClass自己,并将调用得到的返回值返回给用户;
如果"attr"key对应的value没有__get__方法,则返回该value本身。
Properties
Calling property() is a succint way of building a data descriptor that triggers function calls upon acess to an attribute. Its signature is:
property(fget=None, fset=None, fdel=None, doc=None) -> property attribute
Below is a pure Python version of Property Mechanism:
class Property(object):
"Emulate PyProperty_Type() in Objects/descrobject.c"
def __init__(self, fget=None, fset=None, fdel=None, doc=None):
self.fget = fget
self.fset = fset
self.fdel = fdel
if doc is None and fget is not None:
doc = fget.__doc__
self.__doc__ = doc
def __get__(self, obj, objtype=None):
if obj is None:
return self
if self.fget is None:
raise AttributeError("unreadable attribute")
return self.fget(obj)
def __set__(self, obj, value):
if self.fset is None:
raise AttributeError("can't set attribute")
self.fset(obj, value)
def __delete__(self, obj):
if self.fdel is None:
raise AttributeError("can't delete attribute")
self.fdel(obj)
def getter(self, fget):
return type(self)(fget, self.fset, self.fdel, self.__doc__)
def setter(self, fset):
return type(self)(self.fget, fset, self.fdel, self.__doc__)
def deleter(self, fdel):
return type(self)(self.fget, self.fset, fdel, self.__doc__)
property机理描述:
当你使用property()的时候,你实际上获得了Property类的一个实例。Property类在自己的__get__, __set__, __delete__ descriptor methods里嵌入了fget, fset, fdel的逻辑,并用它们来完成相应的get, set, delete操作。而你,通过向property()传入自定义的fget[, fset, fdel]方法,来获得一个间接的自定义descriptor的实例。此外,Property类还提供了getter, setter, deleter方法,供property实例使用。它们的作用机理见如下范例:
class Sample(object):
def __init__(self):
self._val = 153
# 我们申请了一个名字"height", 把它的函数主体作为fget参数传给property()
# property根据此参数, 生成了一个Property的实例
# Sample把"height"作为key放进自己的`__dict__`里,把上一步生成的Property实例作为相对应的value,
# 其代码描述是 Sample.__dict__["height"] = Property(fget=height_func_body)
# 当我们用Sample类生成一个实例sample,并使用sample.height语句时,
# 根据descriptor机理,在一系列中间过程后,
# 我们会去获得type(sample).__dict__('height').__get__(sample, type(sample))的值。
# 所以实际上,我们这儿在调用Property(fget=height_func_body).__get__(sample, type(sample))方法
# 我们再去看Property类里的__get__方法,会发现它在边际条件判断后,返回self.fget(sample)的值。
# 而对于该Property实例而言此处的 fget 就是 height_func_body(一个函数处理逻辑,没有函数名) ,
# 它接受一个参数,并返回该参数的_val属性。
# 所以此处,我们会返回sample._val,该实例并没有_val属性,
# 所以返回type(sample).__dict__['_val']的值,也就是153
#
# PS: height_func_body 是指如下代码逻辑,
# def ____(arg):
# return arg._val
# 上面function命名里的____ 用来代替height, 因为height最后指向的实际是@property处理完后的Property实例。
# 但____也不是此body的函数名,此body有过临时构建函数名,但被消灭了
@property
def height(self):
return self._val
# 我们在这儿用的decorator是height.setter,也就是说我们会把此处的function_body传给height.setter,
# 把获得的返回值挂载在function_name,也就是"height"上,
# 挂载方式是Sample.__dict__[function_name] = decorate_result。
# 此处decorator里的height,实际上是我们之前用@property获得的Property实例。
# Property实例的setter方法是如何运作的呢?我们可以看到他定义了两个传入参数self, 和fset.
# 当我们在Property实例里调用此方法时,第一个参数self实际上被指向了这个Property实例自身。
# setter的逻辑语句只有一行: return type(self)(self.fget, fset, self.fdel, self.__doc__)
# type(self)得到的是Property类,
# 向Property类传入self.fget, fset, self.fdel, self.__doc__ 等参数,我们会得到什么呢?
# Bingo, 一个新Property实例出现了。
# 这个新的Property实例拥有原来的Property实例的`fget, fdel, 和 __doc__`属性,
# 同时将`fset`属性替换为此处传向setter的function_body。
# 根据Decorator的原理,这个新实例的变量名是"height", "height"还是那个"height"只不过它指示的对象已经发生了变化。
# 用一个比喻来形容这个过程就是: 张三被克隆了,给克隆体换了一个器官,把原有的张三消灭,管这个新的克隆体叫张三。
#
# PS: 从理论上讲,如果之前的Property实例被修改了除`fget, fset, fdel, __doc__`以外的属性,
# 新获得的Property实例在使用效果上和老实例不是完全等价的。
# 但我自己做了下实验,发现property实例对attribute修改做了保护,禁止了直接赋值。
# 这样可以确保用`getter, setter, deleter`获得的新实例能尽可能地和原实例保持特性一致
# (因为有方法替换,特性肯定不会完全相同)。
# 如果您找到了在Property实例生成后直接修改其属性的方法,请与我电邮联系: zengjuchen@gmail.com
@height.setter
def height(self, val):
self._val = val
what property() returns is definitely a data descriptor, as it has default __set__ and __get__ method.
References:
如想进一步了解为何上文的height_func_body没有特定函数名,请参见相关的Decorator文档
How @property works?
For experiments about
non-data descriptors, see here
关于object里的__getattribute__如何运行,可以查看~/source_code/PYPY_source_code/pypy/objspace/descroperation.py里第80行Object类的descr__getattribute__方法。
Functions and Methods
Python's object oriented features are built upon a function based environment, by using non-data descriptors.
Class dictionaries store methods as functions.
The only difference between method and function is that method's first argument is reserved for the object instance.
To support method calls, functions include the __get__() method for binding methods during attribute access.
This means that all functions are non-data descriptors which return bound or unbound methods depending whether they are invoked from an object or a class.
In pure python, it works like this:
class Function(object):
# . . .
def __get__(self, obj, objtype=None):
"Simulate fun_descr_get() in Objects/funcobject.c"
return types.MethodType(self, obj, objtype)
Let's see an example:
>>> class E(object):
# self is just a name convention for first arg of functions inside a class, we can also name it x or any other thing.
def f(self_and_x):
print "f is printing: ", self_and_x
>>> e = E()
>>> E.__dict__['f']
<function __main__.f>
>>> E.f
<unbound method E.f>
>>> e.f
<bound method E.f of <__main__.E object at 0x107542a90>>
# When calling from __dict__ of E, f is just a normal function
>>> E.__dict__['f']("function f prints anything you type")
f is printing: function f prints anything you type
# When calling as unbound method of E, f requires an instance of E as first parameter
>>> e2 = E()
>>> E.f(e2)
f is printing: <__main__.E object at 0x1075428d0>
# When calling as bound method of e, f automatically passed the instance itself as first parameter.
>>> e.f()
f is printing: <__main__.E object at 0x107542a90>
The output suggest that bound and unbound methodds are two different types.
But the actual C implementation of PyMethod_Type in Objects/classobject.c is a single representation depending on whether the im_self filed is set or is NULL.
Likewise, the effects of calling a method object depend on the im_self field.
If set(meaning bound), the original function(stored in the im_func field) is called as expected with the first argument set to the instance stored in im_self field.
If unbound, all the arguments are passed unchanged to the original function. But it will raise TypeError if the first arg is not an instance of class.
Let's see examples continuing with the previous example:
# Get the original func by calling im_func attribute
>>> E.f.im_func
<function __main__.f>
>>> E.f.im_func('we can print anything again')
f is printing: we can print anything again
# Unbound method donesn't have im_self value
>>> E.f.im_self is None
True
# Calling im_func from bound method
>>> e.f.im_func
<function __main__.f>
>>> e.f.im_func('im_func attribute of bound method give us func!')
f is printing: im_func attribute of bound method give us func!
# Bound method have im_self value refers to the instance
>>> e.f.im_self is e
True
Static Methods and Class Methods
Static Methods acts just the same like a function, except it is called as an attr of a class/instance.
Meanwhile Class Methods is a bound method, which always passes the Class but not the instance as the first arg to the method,
it can be triggered as an attr of a class/instance.
class E2(object):
def normal_m(arg1):
print arg1
@classmethod
def class_m(arg1):
print arg1
@staticmethod
def static_m(arg1):
print arg1
In [1]: e2 = E2()
In [2]: e2.normal_m()
<__main__.E2 object at 0x107362d90>
In [3]: e2.class_m()
<class '__main__.E2'>
In [4]: e2.static_m()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-4-8273c49c257a> in <module>()
----> 1 e2.static_m()
TypeError: static_m() takes exactly 1 argument (0 given)
In [5]: e2.static_m('static_method act like function')
static_method act like function
The implementation of static method can be illustrate as:
class StaticMethod(object):
"Emulate PyStaticMethod_Type() in Objects/funcobject.c"
def __init__(self, f):
self.f = f
def __get__(self, obj, objtype=None):
return self.f
Talking about class methods, dict.fromkeys() is a good example, below is its pure python equivalent implementation:
class Dict(object):
. . .
def fromkeys(klass, iterable, value=None):
"Emulate dict_fromkeys() in Objects/dictobject.c"
d = klass()
for key in iterable:
d[key] = value
return d
fromkeys = classmethod(fromkeys)
And this is the python equivalent for classmethod():
class ClassMethod(object):
"Emulate PyClassMethod_Type() in Objects/funcobject.c"
def __init__(self, f):
self.f = f
def __get__(self, obj, klass=None):
if klass is None:
klass = type(obj)
def newfunc(*args):
return self.f(klass, *args)
return newfunc
Decorators
what is decorator?
It is a Syntax-Sugar in order to make function/method wrap process more readable. Decorators looks like this:
@dec2
@dec1
def my_func(*args):
pass
when you want to use my_func, you are actually get the result of dec2(dec1(func)).
how to use decorator?
So, first you should make sure your decorators definition runs before your own function runs.
And, then be aware that the decorators were executed starts from the one which is closest to def statement.
Finally you should make sure after all the decorate processes, you should get something callable
decorator features
- When you using decorators, you are actually saying:
OK, I got a var_name, its now refers to a callable object.
Now I'm going to pass it as an argument to a function.
It then will pass the result of it to next function. Until the end of the decorators.
And I will now assign the final result to var_name, now matter whatever it is only if it's callable.
This means, you should take a look of what the decorators do to findout the final result.
e.g.
def evil_decorator(_input):
return curse
def curse(name):
print "Fuck you! " + name
@evil_decorator
def greetings(name):
print "Hello! " + name
Guess what will you got when you use greetings("Mr. White")?
All these processes above runs on the function definition parse-build period.
That is to say, the decorators will run when the function code is imported/parsed, it won't wait until you call the function.Another thing, you may specified serveral parameters in your original defination, but the final obj which the original name refers to,
may take 0 parameters, or a bunch of parameters, amazing, isn't it? It all depends on what decorators give back to you.During the decorating process, the original function can only be called with its obj, not with its name.
Called with name, FAILED.
RESULT: "NameError: global name 'print_2' is not defined"
def switch(func):
return print_2@switch def print_2():
return 2
# Called with obj,
# RESULT: "2, returned the obj of print_2 funciton"
def switch(func):
func()
return func
@switch
def print_2():
return 2
This is to say, the name assiging is the last step of a decorating process.
- What if I called the original function in decorators, will it be an infinite loop? The answer is no.
Only the original function will be triggered, but not the result of all decorate processes.
decorate maker
The @ can takes expressions after it, as it the value returned by expression is a func.
This means you can even use eval after it.
Here is a long expression decorator using eval:
def ev(func):
result = func(555)
return result
@eval("[i for i in globals().values() if hasattr(i, '__name__') and i.__name__ == 'ev'][0]")
def my_print(n):
def print_n():
print n
return print_n
Bitwise operators
A bitwise operation operates on one or more bit patterns or binary numerals
~ (NOT) will reverse 1-0 for a number(if signed int, reverse its sign),
~7meansreverse +0111,
thus we got-1000, which is-8.~7 -8
& (AND) will take two binary numbers, compare every bits of them,
on each position, only when both number has value 1 on it, set that position to 1, else 0.
For example. take 5(binary: 101) AND 11(binary: 1011), what we got will bebinary 0001, that is 1.5 & 11 1
If you'd like only keep last N bit of a int number, you can use Bitwise AND operator to do that:
def get_last_n_bit(target_number, n):
filter_number = int("1"*n, 2)
return filter_number & target_number
| (OR) is similar to &(And), but it will return 1 for each position if more than one number have value 1 on that position.
Thus 5(b: 101) OR 11(b: 1011) should be (b: 1111), that is 15.5 | 11 15
^ (XOR) is similar to |(OR), but it returns 1, only when exactly one number has value 1 on that position.
If two numbers have value 1 on same position will return 0 for that position.
Thus 5(b: 101) XOR 11(b: 1011) should be (b: 1110), that is 14.5 ^ 11 14
For its interesting character, we can use XOR to toggle switch status. Below is a toggleing code.
i = 0
for n in range(6):
i = i ^ 1
print i
1
0
1
0
1
0
(RIGHT SHIFT) will shift every bits of a number to right by specified steps, thus we can shrink it.
If the step exceed max digit positions of that number, the number will be zero.
e.g. for number 5(b: 101), if we>>it by 1, we got0b10(2),>>it by 2, we got0b1(1), etc.5 >> 0 5 5 >> 1 2 5 >> 2 1 5 >> 3 0 5 >> 4 0
<< (LEFT SHIFT) is similar to RIGHT SHIFT, but on different direction, thus it enlarge the number.
For 2(b:10), we excpet2 << 1to beb: 100, which is 4.
We can inspect an interesting phenonemon, it seems to<<a number bynsteps means to mulitply that number with2**n.
Let's test it:def multiply_with_2_powers_n(target_number, n):
return target_number << nfor i in range(100):
for j in range(20): assert multiply_with_2_powers_n(i, j) == i * (2**j)TEST PASSED, NO ASSERTION ERROR ARISED
Built-in Functions
待学习built-in funcs:
format
format的基本格式是[[fill]align][sign][#][0][width][,][.precision][type].
是不是有点懵圈?没关系,把下面的文档看一遍再回来看就差不多了。
用来控制python对象的答应格式,输入必选的target值和可选的自定义format格式参数,返回一个特定格式的字符。
默认的格式是"", 返回的实际上就是str(value)。
这是官方地址
旧版的format感觉是为了和C对接所写的,里面的大部分格式都是关于数字的。
不过我在文档示例里发现了一种padding的format格式写法,其抽象表达式是 "padding符" + "位置符" + "字符总长度"。padding符是你用来作为填充的符号,可以是任意符号。位置符用于指明padding符加于何处,>表示padding加在字符最前面,<表示padding加在字符尾部后, ^表示padding加在字符的两边。字符总长度表示格式化后字符的总长度,它并不是指示增加多少个padding符, 得额外注意。
如果遇到左右padding符不能均分的情况,会优先增加右边的padding符。
如果字符总长度小于原字符长度,format函数将返回原字符。
以下是一些示例:
# 在开头padding
>>> format("X", "*>3")
'**X'
# 在结尾padding
>>> format("X", "*<3")
'X**'
# 在两边padding
>>> format("X", "*^3")
'*X*'
# 左右padding不均等
>>> format("X", '*^4')
'*X**'
# 字符总长度参数小于原字符长度
>>> format("X", '*^1')
'X'
New style format 在python2.7以上的版本里,字符串对象自带的format方法可以支持很多好玩的玩法。
# format with arg index
>>> "I worked in {2}{1}{3}".format("A", "B", "C", "D")
'I worked in CBD'
# arg index can be used multiple times
>>> "If you feel stressed, just say {0}, {0}, {1}".format("Oh", "Ah")
'If you feel stressed, just say Oh, Oh, Ah'
# Using *args to unpack string
>>> "I worked in {2}{1}{3}".format(*"ABCD") # string is an iterater
'I worked in CBD'
# Using *args to unpack list
>>> "I worked in {2}{1}{3}".format(*["A", "B", "C", "D"])
'I worked in CBD'
# Using *args to unpack tuple
>>> "I worked in {2}{1}{3}".format(*("A", "B", "C", "D"))
'I worked in CBD'
# Keyword args format
>>> "I don't {verb} my {noun} very much".format(verb="like", noun="job")
"I don't like my job very much"
# Using **kwargs to unpack keyword args from dict
>>> "I don't {verb} my {noun} very much".format(**{"verb": "hate", "noun": "job"})
"I don't hate my job very much"
# Using keyword args multiple times
>>> "All I wanna say is {verb} {verb} {verb}".format(**{"verb": "love"})
'All I wanna say is love love love'
# Accessing arg's attribute
>>> "This is a {0.__class__}".format("Any string")
"This is a <type 'str'>"
>>> "This is a {my_arg.__class__}".format(my_arg=set([]))
"This is a <type 'set'>"
# Accessing arg's items(LIST)
# 在str.format里,列表取值不支持倒序取值和列表切片取值
>>> '{0[5]}'.format(range(10))
'5'
# Accessing arg's items(DICT)
# 请注意,在用key调用arg的item时, 我们使用的key外面没有单引号或双引号,如果加了会报错,这和一般的从字典里取值有差别。
# 我推测python会自动对`[key name]`里的key name加上引号,从第二个例子里的`pet phrase`取值可以看出来。
>>> "Call {0[num]} to contact {0[name]}".format({'num': 110, 'name': 'Police'})
'Call 110 to contact Police'
>>> Mary = {'name': 'Mary', 'age': 38, 'pet phrase': "Don't be overproud, God is watching you!"}
>>> Jack = {'name': "Jack", 'age': 42, 'pet phrase': "Clean your own ass first!"}
>>> raw_story = """{mom[name]} is my mother, she is {mom[age]} old, once my father {dad[name]} won a chess champion, he went home delightly and speak loudly "Guess who is champion today?!", "{mom[pet phrase]} {dad[name]}", my mom said. This really piss my dad off, he counters back, "{dad[pet phrase]} {mom[name]}." """
>>> formated_story = raw_story.format(dad=Jack, mom=Mary)
>>> print formated_story
# Accessing nested arg items(DICT)
>>> D = {'D2': {'D3': "Mempheis"}}
>>> '{0[D2][D3]}'.format(D)
'Mempheis'
使用新版的format你还可以轻松的将数字转化为各类格式的字符表现形式。
# 百分号表示
>>> '{:.2%}'.format(7/13.0)
'53.85%'
# 用逗号按千为单位分隔数字
>>> '{:,}'.format(123456789)
'123,456,789'
# 将数字以16进制和8进制形式表现
>>> 'hex: {0:#x}, oct: {0:#o}'.format(11)
'hex: 0xb, oct: 0o13'
# 格式化datetime对象
>>> import datetime
>>> now = datetime.datetime.now()
>>> "{0:%S:%M:%H %d-%m-%Y}".format(now)
'30:31:18 15-12-2015'
你还可以在format格式里搞嵌套,以下是两个样例:
>>> fill = '*'
>>> width = 20
>>> for align, text in zip('>^<', ['prefix', 'center', 'suffix']):
>>> print "{0:{fill}{align}{width}}".format(text, align=align, fill=fill, width=width)
**************prefix
*******center*******
suffix**************
width = 8
for num in range(6, 12):
for base in 'dxob':
print "{0:{width}{base}}".format(num, base=base, width=width), # Comma in the end will suppress newline print
print # print mere a newline
对非数字对象使用precision,是表示取该字符的多少位作为本体,通过下面两个例子可以体会一下之前说的格式化字符总长度和precision长度之间的相互关系:
>>> format('abcd', '*^2.5')
'abcd'
>>> format('abcd', '*^8.3')
'**abc***'
chr
输入序号值(0-255),返回相对应的ascii编码。
如果该编码有python里对应的字符,返回该python字符,反之返回'\x' + 16进制数字编码的python-ascii字符表示码。
但是python表示符和python-ascii表示符在python里是等效的,见下例:
>>> chr(9)
'\t'
>>> '\t' is '\x09'
True
>>> print "Let's \t test \x09 it"
Let's test it
这是一个ascii码和相应字符对应表, 我们可以用一些特殊代码在python里做一些好玩的事情,比如:
# '\x08' 是 backspace, 这儿的backspace只移动光标
>>> print '123\x08\x08\x084'
423
# 'x7f' 是第127个ascii 字符,代表DEL, 我们可以用他来删除光标下的字符
>>> print '123\x08\x08\x7f'
1 3
# '\x0b' 是 vertical tab
>>> print "Hello\x0bMy friends.\x0bI'm\x0bVertical Tab!"
Hello
My friends.
I'm
Vertical Tab!
ord
这是chr的反函数,你输入一个字符给它,它会返回该字符相应的ascii码序号
type
You can use type with 1 or 3 arguments.
With type(one_arg), you got the type of one_arg.
If one_arg is an instance, you will get the class of that instance.
But when you want to check the type of object, it's recommended to use isintance(obj, type)
With three args form type(name, bases, dict), a new type object is returned.
TYPE REQUIREMENTS: name -> str, bases -> tuple, dict -> dict.
This is way of dynamically define a class.
The name argument is the name of class and become __name__ attribute.
The bases tuple will itemizes the base classes and become the __bases__ attribute of the class, it will record the class's ancestors.
The dict argument will initiliaze the __dict__ attribute and update its content into it.
Belowing are two identical ways of create a class.
# First way
class X(dict):
a = 1
# Second way
>>> X = type('X', (dict,), {'a': 1})
# The first arg need not to be identical to the variable name, samples like below also works.
>>> Zorro = type('王大锤', (object,), {})
>>> Zorro
__main__.王大锤
super
The basic usage is super(Class, instance), when you use it, the following steps will happen:
- Python check if isinstance(instance, Class) is True.
- Python find the class attribute of instance, get the the instance.class's mro attribute.
- Python find the index of Class you passed to super in the mro tuple in step2.
- Python add the index of step3 by 1, use it to get the corresponding class in mro tuple of step 2, and return the super delegate of this corresponding class.
- If the index in step4 exceed length of mro of step2, the delegate of last class in mro of step2 is returned, which is the object class.
Below is the official doc version about super(Class, instance)'s behaviour:
The call super(B, obj).m() searches obj.__class__.__mro__ for the base class A immediately following B
and then returns A.__dict__['m'].__get__(obj, B). If not a descriptor, m is returned unchanged.
If not in the dictionary, m reverts to a search using object.__getattribute__().
When you used super(Class1, Class2), you will get the delegate whose position is after Class1 in Class2's __mro__ list.
And then you can use the use the delegate to call the according class methods.
Discussions about how super interacts with
__mro__
Single argument on super
dir
When called without arguments, return a list of names of current scope.
If you passed an object to it, it will return a list of names of the attributes of the object.
eval and exec
evalreturns the value of expression,execreturnsNone.evalonly accepts single expression,exechas no limit.
when the input is str, both eval and exec will use compile function to compile it into bytecode first.
The difference is they'll pass different mode arguemnts to compile,eval passes "eval", exec passes "exec", and this made up the two different features we listed above.
raw_input()
convert anything typed-in into string
>>>raw_input()
>>>test \n \t
>>>'test \\n \\t'
input()
Equal to eval(raw_input())
>>>input()
>>>1 + 1
>>>2
pow(a, b)
Equal to a ** b
>>>pow(2, 3)
>>>8
Syntaxs
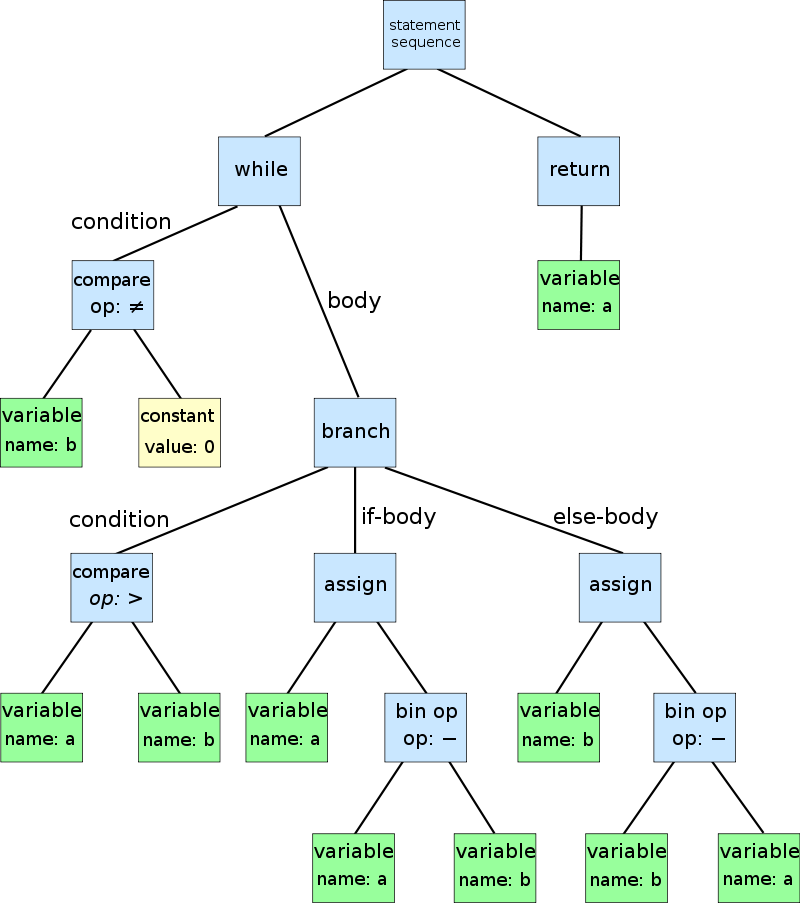
What is AST?
AST is short ofr Abstract Syntax Tree.
It is a tree representation of the abstract syntax structure of a piece of source code.
Below is a piece of pseudo-code and its AST:
# CODE
while b ≠ 0
if a > b
a := a − b
else
b := b − a
return a
AST:
Differences between expressions and statement
Statemens are anything that can make up a line(or several lines) of python code.
Expressions is a subset of statements, it has these features:
- Produce at least 1 value, the value can be any Python object.
- Only contain identifiers, literals and operators.
- Operators include arithmetic and boolean operators, the function call operator () the subscription operator [] and similar,
if condition in 1 line
>>>if "I'm your daddy": print "I'm your daddy"
DATA TYPES
String
Number
Hexadecimals
Hexadecimals starts with 0x
>>>print 0xB
11
Octals
Octals starts with arbitary numbers of 0
>>>print 011
9
>>>0111 == 0000111
True
Hash Object
hashlib.md5('target_txt') will return a hash object with md5 algorithm.
Which stores its value as a 128-bit hash value (binary - data), and other attributes for manipulating this data.
Let's say hash_sample is a hash object with md5 algorithm.
Hash_sample.hexdigest() will transfer the binary into a 32 byte hex string.
Two byte([0-9a-f]) for per 8 bit number(max to 16*16).
(128/8) * 2 = 32
hash_sample.digest() will transfer the object's binary data into a 16 byte string:
By default python tries to interpret the bytes as ascii using the \xhh escape to output the hex representation of any bytes not in the range of ascii.
If there isn't such code in ascii, you'll saw unrecongnizable code on your screen when trying to print it out.
md5 will map the given text to a number between 0 to
2 ** 128
*